
2022-10-20
2022年10月Journal of Vision期刊发布关于视觉搜索的文章,并Featured展示;文章利用VR技术和VR眼动仪,系统考察了真实世界视觉搜索活动中,由于运动导致的物体影像的连续变形对个体搜索过程以及识别表现的影响。中山大学心理学系的潘静教授为该文章通讯作者,博士研究生张慧远为第一作者,上海青研科技提供眼动设备及相应技术支持。

图1:Journal of Vision首页,中山大学团队文章展示
传统表征(建构)主义(representationalism / constructivism)对视知觉的理解是,真实世界的物体在视网膜上投射一个影像(retinal image),视神经将信号传输到大脑,在视觉皮层进行加工,形成心理表征(mental model / representation),依靠以往经验(experience)或计算(computation)进而建构(construct)或推导(infer)出对应的真实世界里的物体是什么。这部分研究者认为,视知觉的起点是物体在视网膜投射的影像。
图2:传统视知觉模型示例图(图源自网络)
然而,生态心理学家认为,知觉研究不能脱离知觉活动的主体,即观察者,以及观察者所处的环境。观察者和环境构成了一个有机的整体,应作为知觉/动作研究的基本单元。生态学派的研究者认为,知觉是基于环境光中的信息,而非基于表征(You don’t need a model for the world. You have access to the real world through the senses)。具体来说,环境里的物体表面反射光,反射光汇聚到一个观察点(point of observation)形成光阵(optic array),光阵里包含了物体表面材质(texture),倾斜度(slant),物体之间空间相对关系(spatial layout)等静态影像信息。当观察者或物体移动,光阵以对应于运动模式的方式规则转换,形成动态光流(optic flow)。真实世界里既有影像结构信息,也有动态光流信息(见下图)。基于表征主义的知觉研究者们将丰富的三维动、静态信息简化成物体的2D投影,以简单影像作为知觉过程的起点,致使至少一半的视觉信息没有被纳入现有的知觉理论模型中。
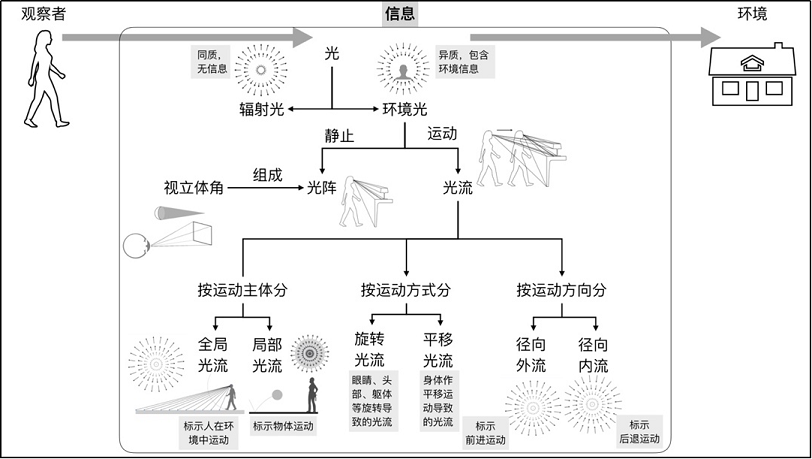
图3:生态光学理论总结。Gibson认为观察者利用环境光里的视觉信息完成知觉任务。环境光里包括静态影像结构信息和动态光流信息(图片来自:潘静、张慧远、陈东濠、徐宏格,2020)
我们几乎每时每刻都在找东西,从衣柜里找衣服,在超市找想买的货品,在手机上找app,马路上找地铁标志,找商店牌子。从上世纪八十年代起,视觉搜索一直是认知研究中一个重要的领域。经典视觉搜索范式大多从矢状面(saggital view)以正投影方式呈现静态2D图示作为搜索对象。而真实环境中,观察者经常从俯视或仰视的角度观察、搜索3D物体,观察者或物体都可能是运动的。观察角度的变化以及观察者和物体之间的相对运动都会导致搜索对象的影像发生变化。例如,下雨天的课后,在教室门口找自己的雨伞(见下图)。我们从远处慢慢靠近雨伞,在这个过程中,雨伞投射到视网膜上的影像始终在变化,但是我们似乎不怎么费力就能找到自己的雨伞。因此,我们在传统视觉搜索任务的基础上,引入了连续的视角变化,来探究其对视觉搜索过程及表现的影响。

图4:日常找雨伞示例图
本课题组使用Unity搭建虚拟现实搜索场景,观察者佩戴HTC Vive头戴式显示器,使用HTC Vive手柄作为反应收集器(见下图)。两个1080×1200 px OLED屏幕的刷新率为90 Hz,总体视野约为100°(水平方向)×110°(垂直方向)。此外,头戴式显示器内置了青研VR眼动仪(型号V1S)。上海青研科技有限公司研发的VR眼动仪(型号:V1S)在以中央凹左右20°窗口内,以100 Hz的刷新率和约0.5°的空间分辨率记录双眼眼动。

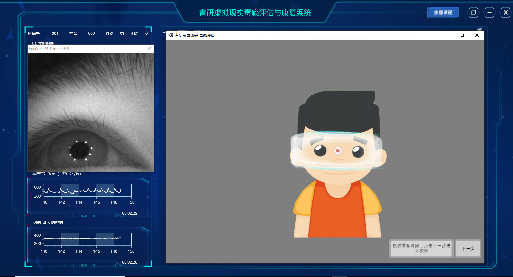
图5:青研科技VR眼动仪及眼动分析软件
在搜索场景中,所有的待搜索物体(相互无遮挡)都放在一个圆形转盘上。在转盘的中心,有一个红色的圆环(直径=4°)。整个场景模拟了坐着的观察者以35°俯视桌子上的物体。在静态条件下,转盘和所有的待搜索物体是静止的;在动态条件下,转台及其支撑的搜索物体在纵深维度上左右旋转。初始时刻,所有物体的正面视图直接面向观察者,转台的旋转速度为12°/s,最大位移为起始位置左右45°(视频如下)。不同场景条件下的每个试次的流程一致:被试首先用3秒钟学习目标,然后出现搜索序列,等待被试按键反应,被试需要使用手柄来做出反应。如果确认当前试次有目标,则扣动手柄下方的扳机;如果确认目标未出现在搜索场景中,则按下手柄上表面的触摸板。随后进入自信评分界面。接着进入下一个试次。

图6:VR静态搜索场景(图片来自:Zhang & Pan,2022)
实验结果
1)无论静态场景或是动态场景,搜索的基本规律与传统视觉搜索的主要结论一致:搜索反应时与项目集大小呈现线性相关;搜索效率在目标不存在的试次和目标存在试次中存在两倍关系,表明搜索过程是序列的、自终止的。
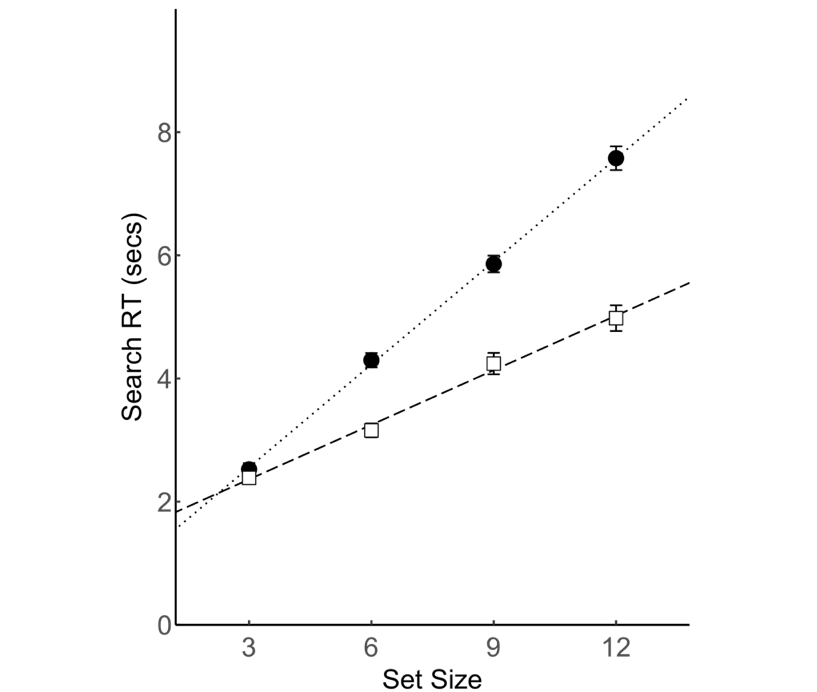
图7:反应时随项目集大小线性增加,但是增长速率在目标存在和目标不存在的搜索中不同。实心圆圈:目标不存在的试次。空心矩形:目标存在的试次。误差线代表一个标准差(图片来自:Zhang & Pan,2022)
2)搜索的表现(准确率、反应时)在两种场景条件下一致;
3)进一步地,场景类型对搜索过程(如拒绝干扰物、识别目标或查看参照物所花费的时间)没有影响,见下图。
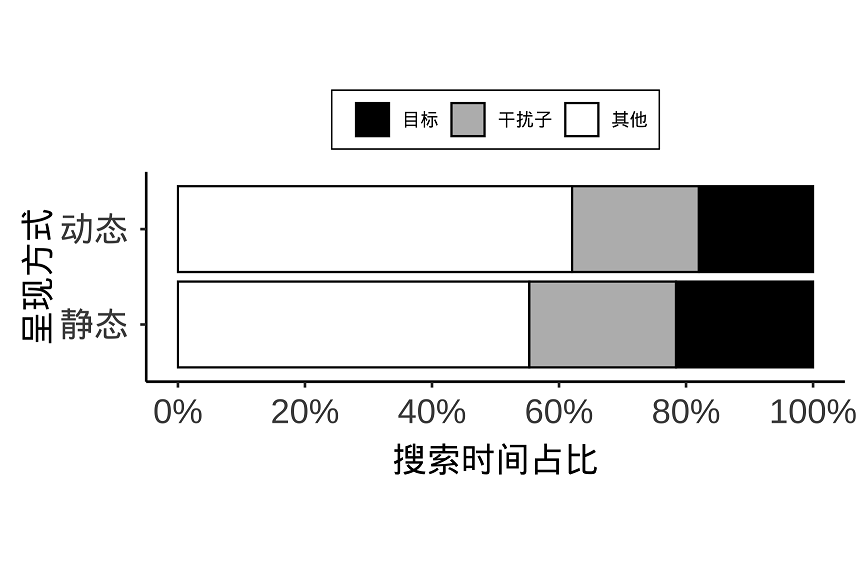
图8:静态和动态场景两种条件下,观察者在目标、干扰子和其他位置上的搜索时间的占比情况。(图片来自:Zhang & Pan,2022)
我们的实验结果表明,连续的视角变化不影响搜索过程和搜索表现。考虑到有无目标外观的精确匹配,参与者的搜索性能在准确性、实时性和效率方面是相当的,视觉搜索过程很可能不是基于视网膜图像的匹配。相反,根据物体的定义特征识别物体,并根据物体的区别特征区分物体,似乎是找到随机形状物体的先决条件。也就是说,视知觉的起点不是视网膜影像,而是基于观察者和环境的互动。
参考文献: Zhang, H., & Pan, J. S. (2022). Visual search as an embodied process: The effects of perspective change and external reference on search performance. Journal of Vision, 22(10):13, 1–23, https://doi.org/10.1167/jov.22.10.13.